论文 Deep Exploration via Bootstrapped DQN 中,作者提出了一种 bootstrapped DQN 的探索方法,将深度探索与深度神经网络相结合,与一些抖动探索策略比如 ε-greedy 相比, 可以指数级地加快学习速度。
Q-Learning with Continuous Actions
在离散行为空间中,Q-learning 的策略选择与目标值为: \[ \pi(a_t|s_t)= \begin{cases} 1 & \quad \text{if } a_t=\arg\max_{a_t}Q_\phi(s_t,a_t)\\ 0 & \quad \text{otherwise} \end{cases}\\ \ \\ y_j=r_j+\gamma\max_{a_j'}Q_{\phi'}(s_j',a_j') \] 但在连续行为空间中,这两者的 \(\max\) 操作就会出现问题。
Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
论文 Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models 提出了一种基于模型的,为 Reward Function 增加 Bonus 的方法来刺激 agent 进行探索。
Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
在 Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks 论文中,作者提出了一种 deep distributed recurrent Q-networks (DDRQN) 方法,它可以解决多个智能体互相之间的交流协作问题,使智能体之间从无到有达成一种交流协议。论文主要针对两个著名的谜题:囚犯帽子谜题 (Hats Riddle) 与 囚犯开关谜题 (Switch Riddle) 来设计解决方案。
Memory-Based Control With Recurrent Neural Networks
部分可观察环境的马尔可夫决策过程 (partially-observed Markov Decision process POMDP) 是强化学习中的一个非常具有挑战性的部分,在 Memory-Based Control With Recurrent Neural Networks 这篇论文中,作者使用了长短时记忆的循环神经网络并扩展了确定性策略梯度 (deterministic policy gradient) 与随机价值梯度 (stochastic value gradient) 两种方法分别称为 RDPG 和 RSVG(0) 来解决 POMDP 问题。
Deep Reinforcement Learning In Parameterized Action Space
论文 Deep Reinforcement Learning In Parameterized Action Space 将 Deep Deterministic Policy Gradient 算法扩展了一下,使 DDPG 可以处理连续的参数化的行为空间 (parameterized action space) 。论文以机器人世界杯 (RoboCup) 的 2D 游戏 Half-Field-Offense (HFO) 为例,构造了深度神经网络并进行训练。
High-Dimensional Continuous Control Using Generalized Advantage Estimation
本文简单介绍一下 High-Dimensional Continuous Control Using Generalized Advantage Estimation 这篇论文。该论文主要做了两件事:
- 使用一种类似于 TD(λ) 的优势函数的估计形式来做到值函数的方差偏差平衡 (bias-variance tradeoff)
- 将置信域优化算法 (trust region optimization) 同时用在策略与值函数的优化上
Tensorflow RNN
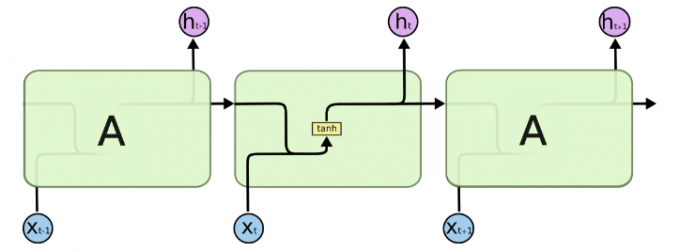
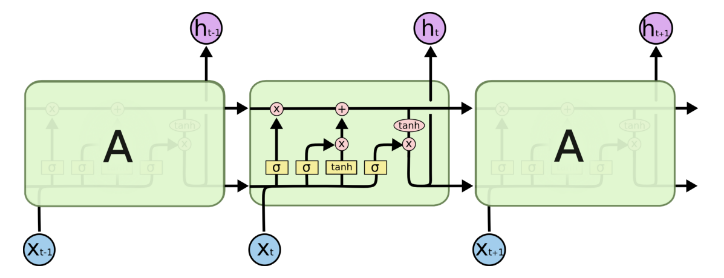
循环神经网络 (Recurrent Neural Networks RNN) 作为一种序列模型非常适合用在处理数据之间有着时间顺序的问题,比如自然语言处理 (NLP) ,Tensorflow 将 RNN 中循环的网络封装为一个细胞 (cell) ,本文简单介绍一下如何构建一个长短期记忆 (Long Short-Term Memory LSTM) 网络。
Proximal Policy Optimization 代码实现
在 Proximal Policy Optimization Algorithms 一文的基础上,可以看出来 PPO 比 TRPO 算法实现起来方便得多,相比于 Actor-Critic 算法,最重要的改动在于把目标函数进行了替换 (surrogate objective) ,同时在更新这个替代的目标函数时对它加上了一定更新幅度的限制。在实际的代码实现中,我们根据论文中的说明,将 Actor 和 Critic 合并起来,共用一套神经网络参数,只用一个损失函数来进行优化。直接看完整代码。
在 https://github.com/BlueFisher/RL-PPO-with-Unity 项目中有更加完善,功能更加强大的 PPO 代码,智能体运行环境基于 Unity ML-Agents Toolkit 。
Proximal Policy Optimization Algorithms
OpenAI 在 Trust Region Policy Optimization 的基础上发表了 Proximal Policy Optimization Algorithms 论文,提出了一种新颖的目标函数 (surrogate objective function) ,通过用随机梯度下降的方法来优化这个函数达到优化策略的目的,称之为 Proximal Policy Optimization (PPO) 。它有着一些 TRPO 的优点但是比 TRPO 实现起来更加简单。
OpenAI 在 2018 年 6 月 25 日发文称,OpenAI Five 击败 Dota 2 业余团队,其中主要的算法便是用了大规模 PPO 算法,使用了 256 个 GPU 和 128,000 个 CPU