本文主要说明在 Kubesphere 自动化生成的 Kubernetes 中,如何监控 GPU ,如何获取每个节点上使用 GPU 的进程信息并将其转换为 Kubernetes 中的 Pod 信息。所有信息数据都由 Kubesphere 生成的 prometheus 进行抓取。
使用 dcgm-exporter 监控集群的 GPU 信息
参考 https://docs.nvidia.com/datacenter/cloud-native/kubernetes/dcgme2e.html#setting-up-dcgm 官方文档:
部署 dcgm-exporter:
1 2 3 4 kubectl create -f https://raw.githubusercontent.com/NVIDIA/gpu-monitoring-tools/2.0.0-rc.12/dcgm-exporter.yaml daemonset.apps/dcgm-exporter created service/dcgm-exporter created
部署 ServiceMonitor:
1 2 3 kubectl create -f https://raw.githubusercontent.com/NVIDIA/gpu-monitoring-tools/2.0.0-rc.12/service-monitor.yaml servicemonitor.monitoring.coreos.com/dcgm-exporter created
如果要将 dcgm-exporter 部署在特定命名空间下,如 kubesphere-monitoring-system ,需要将两个配置文件下载下来,在 metadata 中加入 namespace: "kubesphere-monitoring-system" 即可。
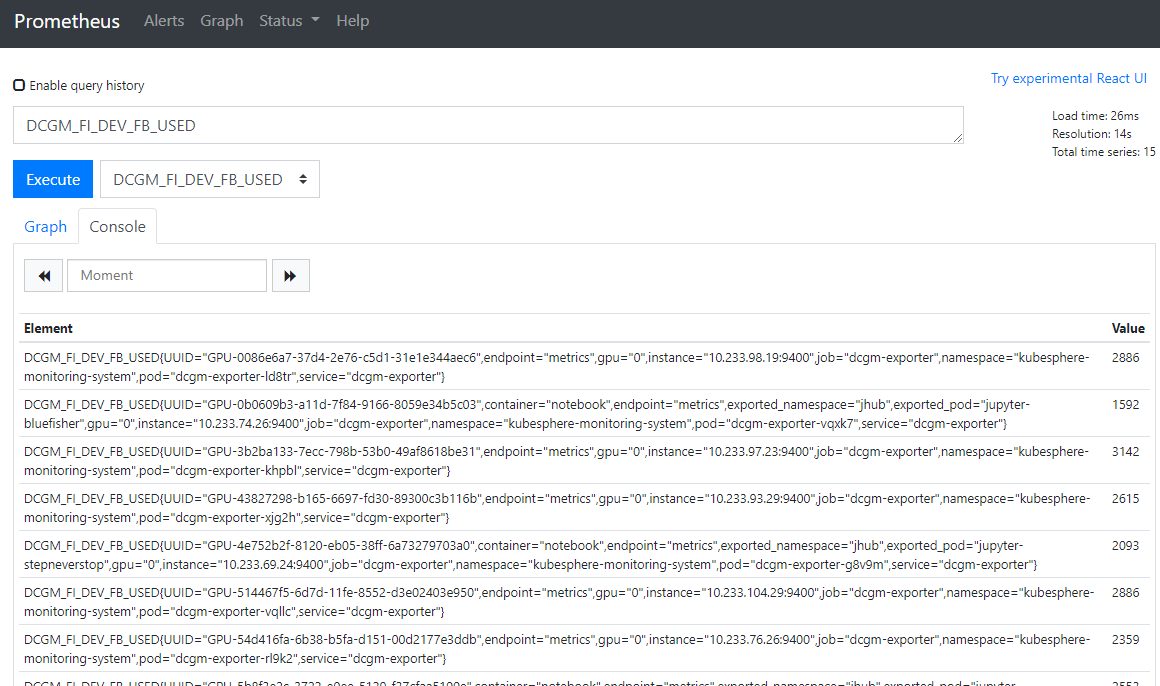
此时,dcgm-exporter 就会以守护进程的方式开启,而 prometheus 服务器会根据 ServiceMonitor 自动抓取 dcgm-exporter 服务器中的数据。如果将 prometheus-k8s 的外网访问打开,可以在网页中看到 dcgm-exporter 收集的 GPU 信息,第一次开启可能需要等待1分钟
如果安装了 Grafana 的话,则可以与 prometheus 联动,进行集群 GPU 的监控
使用自定义 exporter 采集使用显存的 pid,并映射为 Pod 信息
dcgm-exporter 只能用来收集每个物理节点上的 GPU 使用总量,但是无法精确到进程 pid 的粒度,需要自己写采集的代码。
获取 pid
Kubernetes 中普通容器是不能访问到宿主机的进程信息,但只要在配置文件中加上 spec.hostPID: True 即可访问宿主机中所有的进程 pid。
参考 https://kubernetes.io/docs/concepts/policy/pod-security-policy/
此时在容器中执行 nvidia-smi 可以显示所有使用显存的 pid。
根据 pid 获取 Pod 信息
参考 https://blog.csdn.net/alex_yangchuansheng/article/details/107373639
首先获取 pid 对应的容器 id。
1 2 3 4 5 6 7 8 9 10 11 12 # cat /proc/33093/cgroup 11:memory:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 10:blkio:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 9:hugetlb:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 8:pids:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 7:cpuacct,cpu:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 6:perf_event:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 5:cpuset:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 4:freezer:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 3:net_prio,net_cls:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 2:devices:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope 1:name=systemd:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod156e5092_ccaa_41aa_a0b1_bba87ad4d107.slice/docker-85c7e1714cd10dda92e6f2fdef28a94f7ed1ad3783f8238340ea4c7744031afe.scope
可以看到 pid 33093 对应的容器 id 为 85c7e1714c... 。再根据这个容器 id 获取对应 Pod 信息,这需要在容器中执行 kubectl 命令。
在容器中执行 kubectl 命令
参考 https://itnext.io/running-kubectl-commands-from-within-a-pod-b303e8176088
1 2 3 4 5 6 7 FROM debian:busterRUN apt update && \ apt install -y curl && \ curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl && \ chmod +x ./kubectl && \ mv ./kubectl /usr/local /bin/kubectl CMD kubectl get po
pod.yaml
1 2 3 4 5 6 7 8 apiVersion: v1 kind: Pod metadata: name: internal-kubectl spec: containers: - name: internal-kubectl image: trstringer/internal-kubectl:latest
对于这个简单的镜像与配置,如果只是简单的在普通容器中运行 kubectl 命令,会出现运行错误:
1 Error from server (Forbidden): pods is forbidden: User “system:serviceaccount:default:default” cannot list resource “pods” in API group “” in the namespace “default”
Pod 默认是在 default 这个 service account 下运行,而这个 default 是没有权限获取 pod 信息的。如果要列出所有命名空间下的所有 pod 信息,需要创建一个新的 service account 并赋给它获取 pod 信息的权限角色。
service-account.yaml
1 2 3 4 apiVersion: v1 kind: ServiceAccount metadata: name: internal-kubectl
role.yaml,此处是 ClusterRole,可以获取所有命名空间下的所有 Pod 信息,如果要限定在某一命名空间下,则用 Role。
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: modify-pods rules: - apiGroups: [""] resources: - pods verbs: - get - list - delete
role-binding.yaml
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: modify-pods-to-sa subjects: - kind: ServiceAccount name: internal-kubectl namespace: default roleRef: kind: ClusterRole name: modify-pods apiGroup: rbac.authorization.k8s.io
此时修改 pod.yaml,指定刚刚创建的 service account
1 2 3 4 5 6 7 8 9 apiVersion: v1 kind: Pod metadata: name: internal-kubectl spec: serviceAccountName: internal-kubectl containers: - name: internal-kubectl image: trstringer/internal-kubectl:latest
即可列出 Pod 信息。这样如果执行 kubectl get po -o json --all-namespaces 命令,则可以查询出容器 id 对应的 Pod 信息。
nvidia-pid2pod.py
最后需要写一个 exporter 来采集上述所有的 pid, Pod 信息,并供 prometheus 采集,这里给出一个 exporter 的实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 import osimport jsonimport xmltodictfrom flask import Flask, Responsefrom prometheus_client import generate_latest, Gauge, CollectorRegistryCONTENT_TYPE_LATEST = str('text/plain; version=0.0.4; charset=utf-8' ) def get_metrics () : nvidia_smi = os.popen('nvidia-smi -q -x' ).read() nvidia_smi = xmltodict.parse(nvidia_smi) processes = nvidia_smi['nvidia_smi_log' ]['gpu' ]['processes' ] if processes is None : return list() processes_infos = processes['process_info' ] if not isinstance(processes_infos, list): processes_infos = [processes_infos] container_pod = dict() pod_info = os.popen('kubectl get po -o json --all-namespaces' ).read() pod_info = json.loads(pod_info) for pod in pod_info['items' ]: for c in pod['status' ]['containerStatuses' ]: if 'containerID' in c: container_id = c['containerID' ][9 :] container_pod[container_id] = pod metrics = list() for p in processes_infos: try : pid = p['pid' ] except Exception as e: print(p) print(e) continue container_id = os.popen(f'cat /proc/{pid} /cgroup' ).readline().strip().split('/' )[-1 ] if container_id.startswith('docker-' ) and container_id.endswith('.scope' ): container_id = container_id[7 :-6 ] else : print(f'Cannot parse container id {container_id} ' ) exit() if container_id in container_pod: pod = container_pod[container_id] metrics.append({ 'pid' : pid, 'gpu_memory' : int(p['used_memory' ].split(' ' )[0 ]), 'process_name' : p['process_name' ], 'pod_name' : pod['metadata' ]['name' ], 'namespace' : pod['metadata' ]['namespace' ], 'node_name' : pod['spec' ]['nodeName' ] }) return metrics app = Flask(__name__) registry = CollectorRegistry() pid2pod = Gauge( 'nvidia_pid_pod' , 'The GPU usage of each pid and pod mapping' , ['pid' , 'process_name' , 'pod_name' , 'namespace' , 'node_name' ], registry=registry ) @app.route('/metrics', methods=['GET']) def get_data () : for m in get_metrics(): t_pid2pod = pid2pod.labels(m['pid' ], m['process_name' ], m['pod_name' ], m['namespace' ], m['node_name' ]) t_pid2pod.set(m['gpu_memory' ]) return Response(generate_latest(registry=registry), mimetype=CONTENT_TYPE_LATEST) if __name__ == '__main__' : app.run(debug=True , host='0.0.0.0' , port=9400 )
nvidia-pid2pod-exporter.dockerfile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 FROM nvidia/cuda:10.1 -cudnn7-runtime-ubuntu18.04 LABEL maintainer "Fisher <blue_fisher@qq.com>" RUN cp /etc/apt/sources.list /etc/apt/sources.list.bak COPY sources_18.list /etc/apt/sources.list ENV LANG=C.UTF-8 LC_ALL=C.UTF-8 ENV PATH /opt/conda/bin:$PATHRUN apt-get update --fix-missing && apt-get install -y wget bzip2 ca-certificates \ libglib2.0-0 libxext6 libsm6 libxrender1 git \ cmake g++ htop net-tools inetutils-ping curl RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl RUN chmod +x ./kubectl RUN mv ./kubectl /usr/local /bin/kubectl RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh && \ /bin/bash ~/miniconda.sh -b -p /opt/conda && \ rm ~/miniconda.sh && \ /opt/conda/bin/conda clean -tipsy && \ ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh && \ echo ". /opt/conda/etc/profile.d/conda.sh" >> ~/.bashrc && \ echo "conda activate base" >> ~/.bashrc && \ apt-get clean RUN conda update -y conda python RUN . /opt/conda/etc/profile.d/conda.sh && \ conda activate base && \ pip install xmltodict flask prometheus_client COPY nvidia-pid2pod.py /root/nvidia-pid2pod.py EXPOSE 9400 CMD ["python" , "/root/nvidia-pid2pod.py" ]
Pod: nvidia-pid2pod-exporter.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 apiVersion: apps/v1 kind: DaemonSet metadata: name: "nvidia-pid2pod-exporter" namespace: "default" labels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" spec: updateStrategy: type: RollingUpdate selector: matchLabels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" template: metadata: labels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" name: "nvidia-pid2pod-exporter" spec: hostPID: true serviceAccountName: internal-kubectl containers: - image: "10.0.6.14/public/nvidia-pid2pod-exporter:0.1" name: "nvidia-pid2pod-exporter" ports: - name: "metrics" containerPort: 9400 securityContext: runAsNonRoot: false runAsUser: 0 --- kind: Service apiVersion: v1 metadata: name: "nvidia-pid2pod-exporter" namespace: "default" labels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" spec: selector: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" ports: - name: "metrics" port: 9400
与 dcgm-exporter 一样,需要增加一个 nvidia-pid2pod-service-monitor.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: "nvidia-pid2pod-exporter" namespace: "default" labels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" spec: selector: matchLabels: app.kubernetes.io/name: "nvidia-pid2pod-exporter" app.kubernetes.io/version: "0.1" endpoints: - port: "metrics" path: "/metrics"
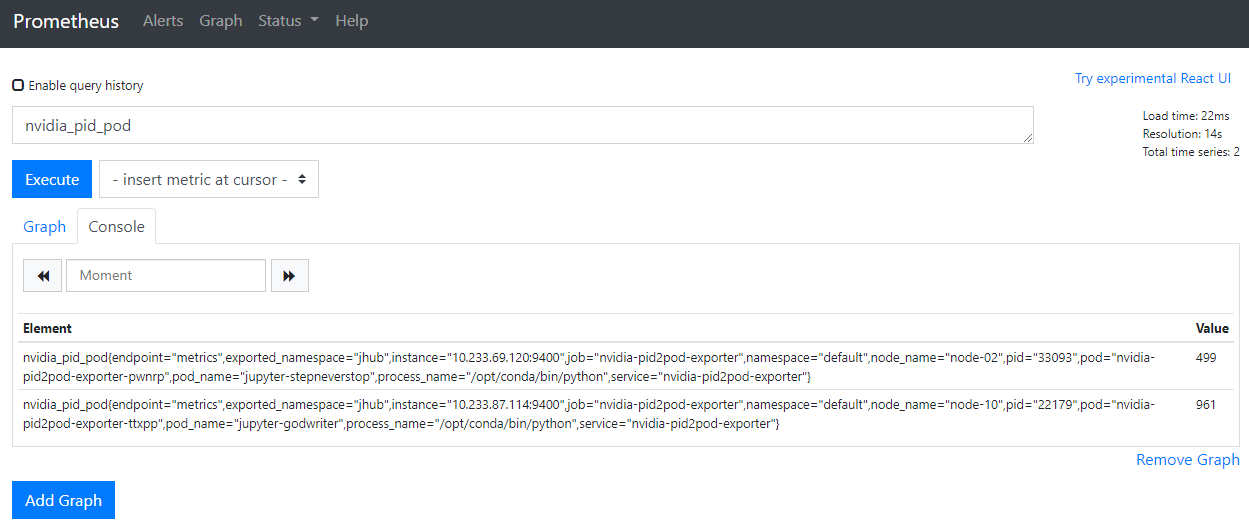
启动完成后耐心等待一分钟,就可以在 prometheus 中看到自定义的信息 nvidia_pid_pod