来自图像的原始输入维度非常高,造成在强化学习中数据利用率非常低效,而来自伯克利的新论文 CURL: Contrastive Unsupervised Representations for Reinforcement Learning 认为如果智能体能在高维的观测信息中学习到更有用的表征,那么基于这些表征所做的强化学习算法将会更加数据高效。该论文主要通过对比学习的方法对高维原始图像输入做表征,能达到可以比肩直接用向量化状态输入的数据利用率。
为了解决数据利用率的问题,主要有两类解决方法:
- 使用辅助任务增强智能体的观测信息
- 构建环境的模型来预测未来
论文中的对比学习属于第一类方法。在标准的 model-free 强化学习前套一层对比学习来学习图像的表征。
对比学习 Contrastive Learning
对比学习最初是应用在图像预训练领域,论文中的对比学习与图像领域有两个区别:1. 没有庞大的无标签图像数据来训练,2. 智能体需要同时运行无监督的对比学习与强化学习。
对比学习可以被视为一种可微的字典查找任务。给定一个 query \(q\) , keys \(\mathbb{K}=\{k_0,k_1,\cdots\}\) ,和 \(\mathbb{K}\) 中的一个关于 \(q\) 的分割 \(P(\mathbb{K}) = (\{k_+\}, \mathbb{K} \backslash \{k_+\})\) ,对比学习的目标就是让 \(q\) 相对于其余 keys \(\mathbb{K} \backslash \{k_+\}\) 更能匹配到 \(k_+\) 。
\(q, \mathbb{K}, k_+, \mathbb{K} \backslash \{k_+\}\) 也被称为 anchor, targets, positive, negatives。anchor 与 targets 之间的相似度可以用点积来衡量 \(q^T k\) ,或者也可以用双线性积 (bilinear products) 来衡量 \(q^TWk\) 。其他诸如欧氏距离也比较常用。整个对比学习的损失可以被定义为:
\[ \mathcal{L}_{q}=\log \frac{\exp \left(q^{T} W k_{+}\right)}{\exp \left(q^{T} W k_{+}\right)+\sum_{i=0}^{K-1} \exp \left(q^{T} W k_{i}\right)} \]
其实就是负的交叉熵损失,或者是 K 分类问题的 log 损失,标签是 \(k_+\)。
CURL Implementation
总体的训练结构为:
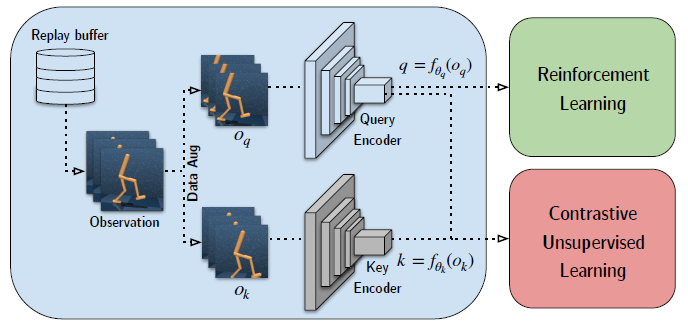
先从经验池中取出一批原始图像数据,对比学习中的 anchor 和 positive 为该原始图像两次不同增强后的结果,增强可以是简单的图像裁剪方式。与图像领域不同的是,需要像 DQN 中的那样把前后几帧的图像拼接起来作为一个观测输入。这样就得到了增强后的 \(o_q, o_k\) ,经过 CNN 的表征后分别得到 \(q,k\) 。由于取出的一批数据,那么得到的也是一批 \(q,k\) ,对比学习就是要让 \(q_i\) 与 \(k_i\) 更相似,而与其他的更不相似,或者说要让 \(q_i\) 尽可能归到到 \(k_i\) 分类下。在对比学习的同时,\(q\) 也作为隐状态,使用 SAC 或 Rainbow DQN 进行强化学习的训练。
需要注意的是,Key Encoder 这层 CNN \(f_{\theta_k}\) 是固定不变的,在对比学习过程中梯度不在这层进行反向传播,类似于 DQN 中的 target 网络。 \(f_{\theta_k}\) 是用一种 Target Encoding with Momentum 的方法来进行更新,训练一开始,\(f_q=f_k\), 随着 \(f_q\) 的更新,根据 \(\theta_{k}=m \theta_{k}+(1-m) \theta_{q}\) 来更新 \(f_k\) 的参数,实际上就是 DDPG 中使用到的 soft update。
实验结果
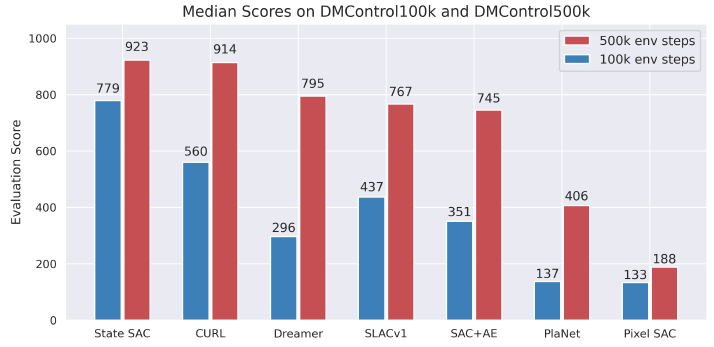
通过这个对比可以看书,用图像输入的 CURL 非常接近直接用向量化状态输入的 SAC,效果还是非常好的。
参考
Srinivas, A., Laskin, M., & Abbeel, P. (2020). CURL: Contrastive Unsupervised Representations for Reinforcement Learning. ArXiv:2004.04136 [Cs, Stat]. http://arxiv.org/abs/2004.04136

