DeepMind 在 ICLR 上发表了 Distributed Prioritized Experience Replay ,可以让强化学习算法更有效地利用大规模数据。文章的思想很简单,算法将强化学习分为行为产生器 actor 和学习器 learner ,每个 actor 独立的与环境进行交互,但行为根据一个共享的网络生成,然后将累积的经验存在共享的经验池 experience replay memory 中;learner 从经验池中采样经验并进行学习,然后更新共享的神经网络参数。整个架构建立在 prioritized experience replay 的基础上。
目前非常多的强化学习研究都比较关注在一台机器上提高算法的性能,但如何更好地利用资源还没有被很多研究过。一些标准的分布式神经网络训练方法都是想要并行地计算梯度,但这篇文章只是想要分布式地生成选取经验数据,尽管两种方法可以进行结合,但本文只探讨了后者方法,而这已经可以大幅提高算法性能。文章将这种分布式架构用在了两个经典使用经验回放机制的算法上:DQN、DDPG。
Distributed Prioritized Experience Replay
在 Massively Parallel Methods for Deep Reinforcement Learning 论文中,DeepMind 将强化学习分为了两个部分,可以同时运行并且不需要非常复杂的同步机制。第一部分为与环境交互,评价基于深度神经网络的策略,并将观测到的数据储存在经验池中。我们把这第一部分称为 acting 。第二部分为从经验池中采样数据并更新策略参数,我们把这一部分称为 learning 。
在论文中,数以百计的 actor 分布式地运行在 CPU 上,与环境进行交互来生成数据,但只有一个 learner 运行在 GPU 上采样最有用的经验。
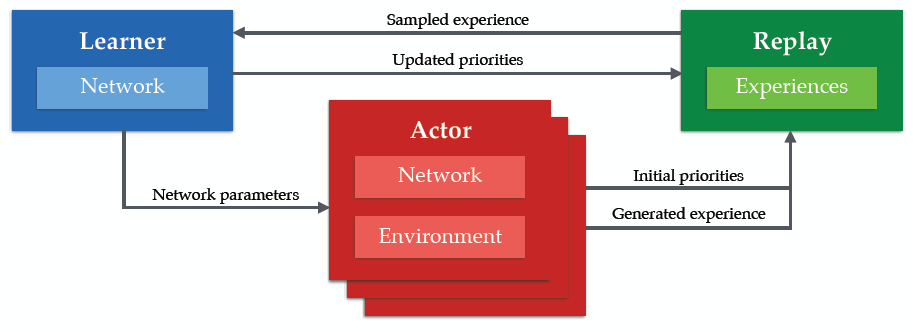
具体的算法为:


更新的神经网络参数会周期性地在 actor 与 learner 之间进行交互。
与 Massively Parallel Methods for Deep Reinforcement Learning 不同的是,我们用一个共享的、中心化的经验池,同时并不是等概率地从经验池中采样,而是有优先级的。除此之外,我们可以给不同的 actor 不同的探索策略,来丰富经验。
参考
Horgan, Dan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silver. “Distributed Prioritized Experience Replay.” ArXiv:1803.00933 [Cs], March 2, 2018. http://arxiv.org/abs/1803.00933.

