本文简单介绍两篇论文:Progressive Neural Networks 和 PathNet: Evolution Channels Gradient Descent in Super Neural Networks 。都出自于 Google DeepMind ,主要侧重于修改网络模型来解决针对强化学习中的迁移学习问题。
Progressive Neural Networks
微调 (finetuning) 网络模型的方法是迁移学习中的一个常用的方法,一般都是先在源任务中训练好一个神经网络,再在目标任务中利用反向传播微调整个网络模型。但这种微调的方法不大适合在多任务中进行迁移学习,比如我们希望汲取多个任务中的知识然后把这些知识迁移到新任务中,同时这种方法也非常容易使得网络模型忘记之前学习得到的知识。
作者提出了 progressive networks 可以克服以上缺点,它显式地架构了不同任务之间的迁移。整个网络架构十分简单,就一幅图:
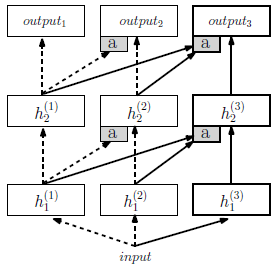
Progressive network 一开始就是一个普通的单列神经网络,有 \(L\) 层,包含 \(h_i^{(1)}\in\mathbb{R}^{n_i}\) 个隐藏层,其中 \(n_i\) 是第 \(i\le L\) 层的单元数量,用 \(\Theta^{(1)}\) 表示训练完毕的第一列神经网络参数。
当切换到第二个任务时, \(\Theta^{(1)}\) 被锁住不动,并且整个网络新增加一列, \(\Theta^{(2)}\) 开始随机初始化。 \(h_i^{(2)}\) 层同时接受来自 \(h_{i-1}^{(2)}\) 和 \(h_{i-1}^{(1)}\) 的横向连接,推广到 \(K\) 个任务用如下公式来表示: \[ h_i^{(k)}=f\left( W_i^{(k)}h_{i-1}^{(k)} + \sum_{j<k}U_i^{(k:j)}h_{i-1}^{(j)} \right) \] 强化学习中,每一列可以用来训练一个特定的 MDP ,相当于第 \(k\) 列代表一个策略 \(\pi^{(k)}(a|s)\) ,输入为状态 \(s\) ,\(\pi^{(k)}(a|s)=h_L^{(k)}(s)\) 。
在实践中,我们会修改一下上述公式,增加一个 adapter 也就是图中的灰色 a 方块,它能既增强初始化条件又能降维: \[ h_i^{(k)}=f\left( W_i^{(k)}h_{i-1}^{(k)} + U_i^{(k:j)}\sigma(V_i^{(k:j)}\alpha_{i-1}^{(<k)}h_{i-1}^{(<k)}) \right) \] 其中 \(h_{i-1}^{(<k)}=[h_{i-1}^{(1)}\cdots h_{i-1}^{(j)} \cdots h_{i-1}^{(k-1)}]\) 。再将之前的横向网络传入当前多层感知机之前,先乘以一个学习标量,用来调整之前横向层的影响程度。\(V_i^{(k:j)}\) 是一个射影矩阵,用来进行降维,使得随着 \(k\) 越来越多,但横向连接的参数数量与 \(|\Theta^{(1)}|\) 相同,在卷积神经网络中,它可以为 \(1 \times 1\) 卷积层。
当然 progressive networks 也有一些而问题,其中最大的问题是随着任务数量的增加,神经网络的参数量会越来越多。
PathNet
DeepMind 随后提出了 PathNet 网络,一种超大规模的神经网络。相较于上文中的 progressive networks 一个任务增加一列神经网络,PathNet 直接预先构建好一个 \(L\) 层的模块化的神经网络,每层有 \(M\) 个模块,每个模块本身就是一个神经网络,可以是卷积神经网络或者其他类型的网络结构。
具体的学习过程可以用下图来表示,绿色块表示一个独立的神经网络模块:
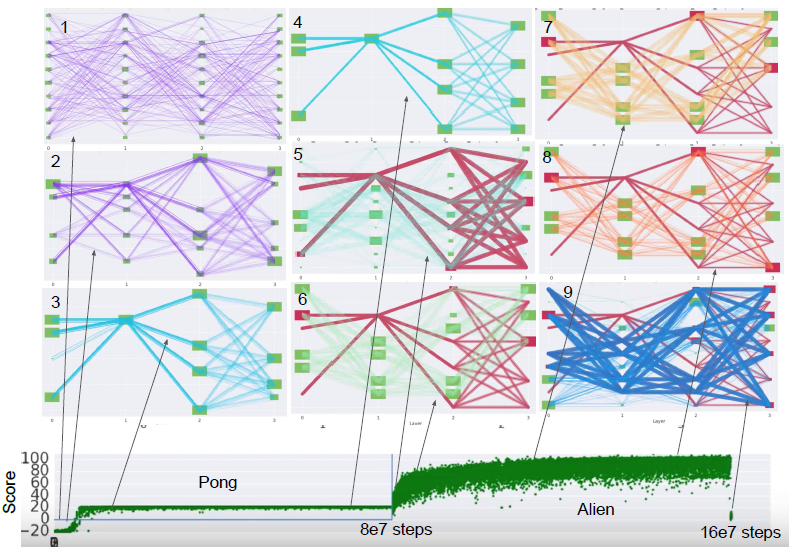
一共训练了两个任务,第一个任务为 Pong 第二个为 Alien 。每个任务都连续地训练 80M 时间长度。Box 1 的紫色路径展现了训练开始时的随机初始化,接着使用强化学习算法训练几个回合游戏,同时用锦标赛选择算法来进化网络路径,因此进化与学习同时进行。Box 2 展示了有一点收敛之后的情况,会发现一些路径已经有些重叠。最终收敛的状态如 Box 3 所示,只会经过一条路径,Box 4 展示出接下来的训练中,单条路径会一直保持到训练结束。这时切换到第二个任务,同时 Pong 的路径会被冻结,也就是说 Pong 路径上的神经网络模块参数不会改变。Box 5 用深红色路径表示被冻结的路径,用淡蓝色表示随机初始化的路径。新路径在 Box 8 中进化到收敛的状态,160M 步训练之后,Alien 游戏的最优路径被固定,如 Box 9 所示。
从图中可以看到,当一个模块出现在路径中时就称之为被激活了。作者在实验中发现每一层最多有 3 个或 4 个模块被激活,而最后一层比较特殊,每个任务之间不会进行共享,会被单独训练。
PathNet 可以用在许多迁移学习中,下图展示了在强化学习的 Atari 游戏环境下的网络架构:
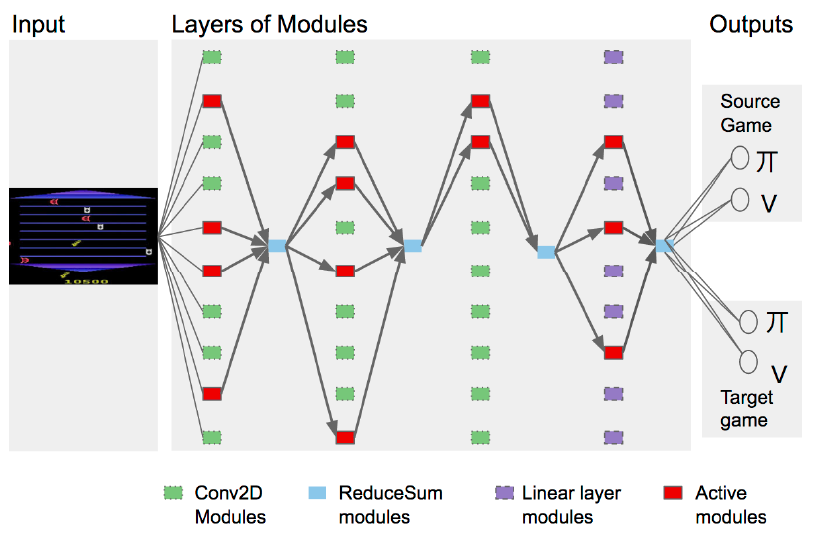
该 PathNet 网络架构用了 4 层,每层包含 \(M=10\) 个模块,前三层绿色的都为卷积神经网络,最后一层紫色的为全连接网络,具体配置可以参考论文。在 PathNet 的每一层之间,被激活的红色模块输出会进行累加,再输入到下一层中,图中显示为蓝色的方块。输出层由于不会共享网络参数,所以单独列在最右边,每个 Atari 游戏都独有一个输出层。
参考
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., ... & Hadsell, R. (2016). Progressive neural networks. arXiv preprint arXiv:1606.04671.
Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A. A., ... & Wierstra, D. (2017). Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734.

